Introduction
In Carola Lilienthal‘s talk about architecture and technical debt at Herbstcampus 2017, I was reminded that I wanted to implement some of the examples of her book “Long-lived software systems” (available only in German) with the structural analysis tool jQAssistant. Especially the visualizations of the dependencies between different business subdomains seemed like a great starting point to try out some stuff. In Carola’s book, there are visualizations like the following:
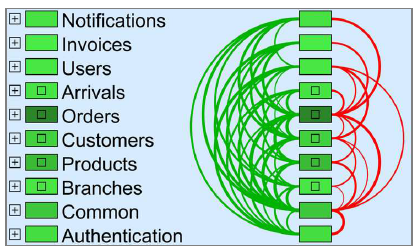
This visualization was created by using SotoGraph, a tool for software architecture validation. It shows the user-defined subdomains as well as the relationships between them. The green connections between the modules show the downward dependencies to other modules and the red one the upward dependencies. This visualization can help if you want to further modularize your system towards microservices or to identify unwanted dependencies between modules.
After Carola’s talk (aka during the rest of the conference’s morning), I immediately created the Java Type Dependency Analysis with visualizations in D3. During coding, I realized that there it is only a small step to analyze dependencies between business subdomains.
What’s missing is the information which type belong to which business subdomain. We’ll find out now!
A simple case study
Once, I’ve developed a party planning application called DropOver (that didn’t go live, but that’s another story) within a small team. We wrote that web application in Java and paid especially attention to structuring the code along the business’ subdomain “partying”. This led to this package structure that resembles the main parts of the application:
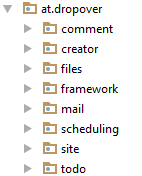
The application’s main entry point is a site for a party including location, time, the site’s creator and so on. A user can comment on a site as well as add some specific widgets like todo lists, scheduling or files upload and also gets notified by the mail feature. And there is a special package framework where all the cross-cutting concerns are placed like the dependency injection configuration or common, technical software elements for persisting data.
The main point to take away here is that it’s easy to determine the business subdomain for a software element thanks to the alignment of the package structure along the business’ subdomain: It’s the 3rd position in the Java package name:
at.dropover.<subdomain>.
This information can easily be used to retrieve the information about the subdomain.
Software from a graph’s perspective
I’ve built the web application, scanned the software artifact (a standard JAR file that we created for integration testing purposes) with the jQAssistant command line tool (with jqassistant.sh scan -f dropover-classes.jar in this case) and started the server (with jqassistant.sh server). Taking a look at the accompanied Neo4j browser, we can see the graph that jQAssistant stored in Neo4j. E. g. we can display the relationship between the JAR file and the contained Java types:
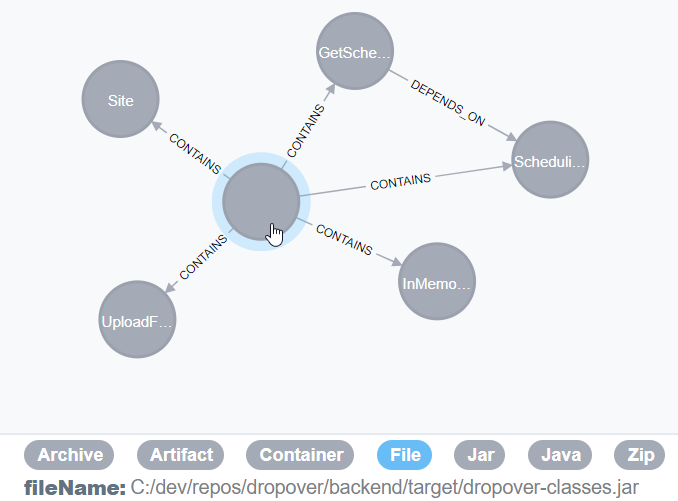
In the following, I set up the connection between my Python glue code and the Neo4j database. The query executed lists simply all Java types of the application (aka the JAR artifact). As mentioned above, we can also get the information about the subdomain derived from the package name:
In [1]:
import py2neo import pandas as pd query=""" MATCH (:Jar:Archive)-[:CONTAINS]->(type:Type) RETURN type.fqn AS type, SPLIT(type.fqn, ".")[2] AS subdomain """ graph = py2neo.Graph() subdomaininfo = pd.DataFrame(graph.run(query).data()) subdomaininfo.head()
Out[1]:
| subdomain | type | |
|---|---|---|
| 0 | scheduling | at.dropover.scheduling.interactor.GetSchedulings |
| 1 | scheduling | at.dropover.scheduling.interactor.validation.S… |
| 2 | site | at.dropover.site.entity.Site |
| 3 | files | at.dropover.files.boundary.UploadFileRequestModel |
| 4 | scheduling | at.dropover.scheduling.entity.gateway.inmemory… |
Gathering dependencies between subdomains
The request returns the corresponding subdomain for each type. It collects all direct dependencies from one type to all other types and returns only the 3rd position of the package name (fqn: full qualified name) of the type and the direct dependency – that means the subdomains of each.
Combined with the approach in Java Type Dependency Analysis, we can now visualize the dependencies between the various subdomains.
In [2]:
import json query=""" MATCH (:Jar:Archive)-[:CONTAINS]-> (type:Type)-[:DEPENDS_ON]->(directDependency:Type) <-[:CONTAINS]-(:Jar:Archive) RETURN SPLIT(type.fqn, ".")[2] AS name, COLLECT(DISTINCT SPLIT(directDependency.fqn, ".")[2]) AS imports """ graph = py2neo.Graph() json_data = graph.run(query).data() with open ( "vis/flare-imports.json", mode='w') as json_file: json_file.write(json.dumps(json_data, indent=3)) json_data[:2]
Out[2]:
[{'imports': ['comment', 'framework', 'creator', 'site'], 'name': 'comment'},
{'imports': ['site', 'mail', 'framework', 'creator'], 'name': 'mail'}]
Discussion
In the output (that you can find here as well), we can see the dependencies between the various subdomains by hovering / touching one of the subdomains’ text labels.
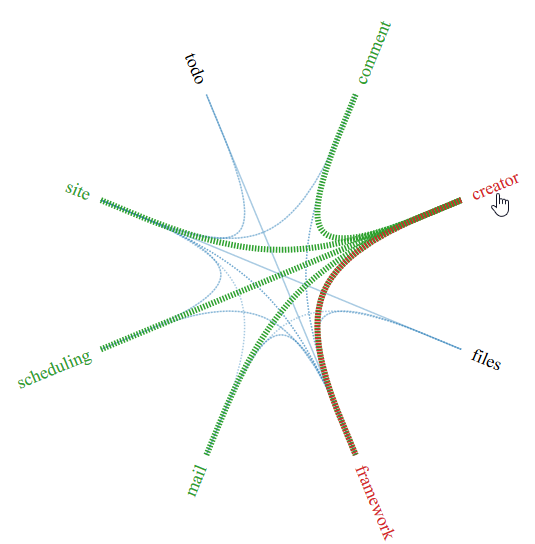
From the visualization above, we can see that the creator subdomain is used by Java source code from the subdomains comment, site, scheduling, mail and framework. The first four make perfect sense because if you create one of those content types in the application, they are created by some person (they are “personalized” content). Whereas todo and files are user agnostic content types and thus don’t have any dependencies on creator (well, that’s a tricky situation in retrospect; wouldn’t do that now).
What could look like a mess are the dependencies from and to framework. In the pseudo subdomain framework, there are some base classes for all the data objects that are persistent in a data store. That explains the outbound dependency of creator. The dependencies from framework to creator are needed for the central dependency injection configuration of the application. So this seems reasonable as well but also can be improved by further dividing the big framework package to smaller, more specific ones.
Where it get’s interesting is the following visualization of the dependencies of the subdomain site:
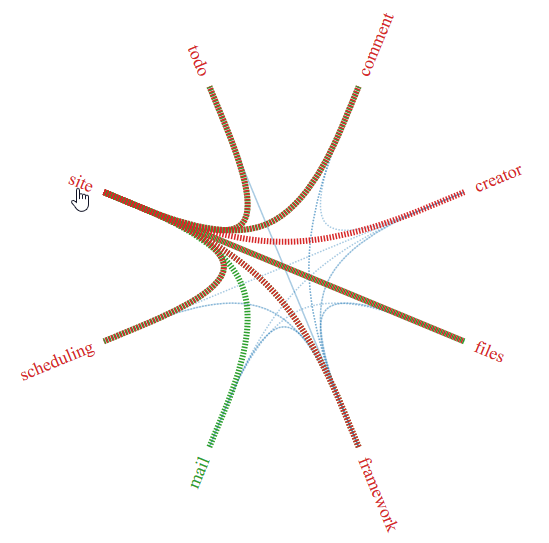
A site is the central point of the application. Almost everything else depends on it (except mail, which is implemented in an interceptor style / aspect). But site is also depending on some of its content. This could be a sign of a design flaw and should be investigated further.
Summary
In this blog post, we’ve learned how you can visualize dependencies between subdomains with jQAssistant / Neo4j. It’s an easy way to quickly get an overview over the subdomain’s relationships.
In the case study, we got lucky because we were able to use the package naming conventions for retrieving the subdomain information. In another post, I’ll show how you can get that information for classes that don’t follow such a naming convention by using some Python’n’Pandas glue code.
Albeit the nice visualization, my recommendation is not to invest too much time into analyzing unwanted dependencies graphically. Tools like jQAssistant provide the means to check for unwanted dependencies automatically during your build process. With this feature, you can let fail the build in case of violations and track the untangling progress of your system, too.
Pingback:Higher-Level Abstractions with jQAssistant and Neo4j – feststelltaste
Pingback:Building Higher-Level Abstractions with jQAssistant and Neo4j – feststelltaste