Introduction
In my previous blog post, we’ve seen how we can identify files that change together in one commit.
In this blog post, we take the analysis to an advanced level:
- We’re using a more robust model for determining the similarity of co-changing source code files
- We’re checking the existing modularization of a software system and compare it to the change behavior of the development teams
- We’re creating a visualization that lets us determine the underlying, “hidden” modularization of our software system based on conjoint changes
- We discuss the results for a concrete software system in detail (with more systems to come in the upcoming blog posts).
We’re using Python and pandas as well as some algorithms from the machine learning library scikit-learn and the visualization libraries matplotlib, seaborn and pygal for these purposes.
The System under Investigation
For this analysis, we use a closed-source project that I developed with some friends of mine. It’s called “DropOver”, a web application that can manage events with features like events’ sites, scheduling, comments, todos, file uploads, mail notifications and so on. The architecture of the software system mirrored the feature-based development process: You could quickly locate where code has to be added or changed because the software system’s “screaming architecture”. This architecture style lead you to the right place because of the explicit, feature-based modularization that was used for the Java packages/namespaces:
It’s also important to know, that we developed the software almost strictly feature-based by feature teams (OK, one developer was one team in our case). Nevertheless, the history of this repository should perfectly fit for our analysis of checking the modularization based on co-changing source code files.
The main goal of our analysis is to see if the modules of the software system were changed independently or if they were code was changed randomly across modules boundaries. If the latter would be the case, we should reorganize the software system or the development teams to let software development activities and the surrounding more naturally fit together.
Idea
We can do this kind of analysis pretty easily by using the version control data of a software system like Git. A version control system tracks each change to a file. If more files are changed within one commit, we can assume that those files somehow have something to do with each other. This could be e. g. a direct dependency because two files depend on each other or a semantic dependency which causes an underlying concepts to change across module boundaries.
In this blog post, we take the idea further: We want to find out the degree of similarity of two co-changing files, making the analysis more robust and reliable on one side, but also enabling a better analysis of bigger software systems on the other side by comparing all files of a software system with each other regarding the co-changing properties.
Data
We use a little helper library for importing the data of our project. It’s a simple git log with change statistics for each commit and file (you can see here how to retrieve it if you want to do it manually).
from lib.ozapfdis.git_tc import log_numstat
GIT_REPO_DIR = "../../dropover_git/"
git_log = log_numstat(GIT_REPO_DIR)[['sha', 'file']]
git_log.head()
In our case, we only want to check the modularization of our software for Java production code. So we just leave the files that are belonging to the main source code. What to keep here exactly is very specific to your own project. With Jupyter and pandas, we can make our decisions for this transparent and thus retraceable.
prod_code = git_log.copy()
prod_code = prod_code[prod_code.file.str.endswith(".java")]
prod_code = prod_code[prod_code.file.str.startswith("backend/src/main")]
prod_code = prod_code[~prod_code.file.str.endswith("package-info.java")]
prod_code.head()
Analysis
We want to see which files are changing (almost) together. A good start for this is to create this view onto our dataset with the pivot_table method of the underlying pandas’ DataFrame.
But before this, we need a marker column that signals that a commit occurred. We can create an additional column named hit for this easily.
prod_code['hit'] = 1
prod_code.head()
Now, we can transform the data as we need it: For the index, we choose the filename, as columns, we choose the unique sha key of a commit. Together with the commit hits as values, we are now able to see which file changes occurred in which commit. Note that the pivoting also change the order of both indexes. They are now sorted alphabetically.
commit_matrix = prod_code.reset_index().pivot_table(
index='file',
columns='sha',
values='hit',
fill_value=0)
commit_matrix.iloc[0:5,50:55]
As already mentioned in a previous blog post, we are now able to look at our problem from a mathematician’ s perspective. What we have here now with the commit_matrix is a collection of n-dimensional vectors. Each vector represents a filename and the components/dimensions of such a vector are the commits with either the value 0 or 1.
Calculating similarities between such vectors is a well-known problem with a variety of solutions. In our case, we calculate the distance between the various vectors with the cosines distance metric. The machine learning library scikit-learn provides us with an easy to use implementation.
from sklearn.metrics.pairwise import cosine_distances
dissimilarity_matrix = cosine_distances(commit_matrix)
dissimilarity_matrix[:5,:5]
To be able to better understand the result, we add the file names from the commit_matrix as index and column index to the dissimilarity_matrix.
import pandas as pd
dissimilarity_df = pd.DataFrame(
dissimilarity_matrix,
index=commit_matrix.index,
columns=commit_matrix.index)
dissimilarity_df.iloc[:5,:2]
Now, we see the result in a better representation: For each file pair, we get the distance of the commit vectors. This means that we have now a distance measure that says how dissimilar two files were changed in respect to each other.
Visualization
Heatmap
To get an overview of the result’s data, we can plot the matrix with a little heatmap first.
%matplotlib inline
import seaborn as sns
sns.heatmap(
dissimilarity_df,
xticklabels=False,
yticklabels=False
);

Because of the alphabetically ordered filenames and the “feature-first” architecture of the software under investigation, we get the first glimpse of how changes within modules are occurring together and which are not.
To get an even better view, we can first extract the module’s names with an easy string operation and use this for the indexes.
modules = dissimilarity_df.copy()
modules.index = modules.index.str.split("/").str[6]
modules.index.name = 'module'
modules.columns = modules.index
modules.iloc[25:30,25:30]
Then, we can create another heatmap that shows the name of the modules on both axes for further evaluation. We also just take a look at a subset of the data for representational reasons.
import matplotlib.pyplot as plt
plt.figure(figsize=[10,9])
sns.heatmap(modules.iloc[:180,:180]);

Discussion
- Starting at the upper left, we see the “comment” module with a pretty dark area very clearly. This means, that files around this module changed together very often.
- If we go to the middle left, we see dark areas between the “comment” module and the “framework” module as well as the “site” module further down. This shows a change dependency between the “comment” module and the other two (I’ll explain later, why it is that way).
- If we take a look in the middle of the heatmap, we see that the very dark area represents changes of the “mail” module. This module was pretty much changed without touching any other modules. This shows a nice separation of concerns.
- For the “scheduling” module, we can also see that the changes occurred mostly cohesive within the module.
- Another interesting aspect is the horizontal line within the “comment” region: These files were changed independently from all other files within the module. These files were the code for an additional data storage technology that was added in later versions of the software system. This pattern repeats for all other modules more or less strongly.
With this visualization, we can get a first impression of how good our software architecture fits the real software development activities. In this case, I would say that you can see most clearly that the source code of the modules changed mostly within the module boundaries. But we have to take a look at the changes that occur in other modules as well when changing a particular module. These could be signs of unwanted dependencies and may lead us to an architectural problem.
Multi-dimensional Scaling
We can create another kind of visualization to check
- if the code within the modules is only changed altogether and
- if not, what other modules were changed.
Here, we can help ourselves with a technique called “multi-dimensional scaling” or “MDS” for short. With MDS, we can break down an n-dimensional space to a lower-dimensional space representation. MDS tries to keep the distance proportions of the higher-dimensional space when breaking it down to a lower-dimensional space.
In our case, we can let MDS figure out a 2D representation of our dissimilarity matrix (which is, overall, just a plain multi-dimensional vector space) to see which files get change together. With this, we’ll able to see which files are changes together regardless of the modules they belong to.
The machine learning library scikit-learn gives us easy access to the algorithm that we need for this task as well. We just need to say that we have a precomputed dissimilarity matrix when initializing the algorithm and then pass our dissimilarity_df DataFrame to the fit_transform method of the algorithm.
from sklearn.manifold import MDS
# uses a fixed seed for random_state for reproducibility
model = MDS(dissimilarity='precomputed', random_state=0)
dissimilarity_2d = model.fit_transform(dissimilarity_df)
dissimilarity_2d[:5]
The result is a 2D matrix that we can plot with matplotlib to get a first glimpse of the distribution of the calculated distances.
plt.figure(figsize=(8,8))
x = dissimilarity_2d[:,0]
y = dissimilarity_2d[:,1]
plt.scatter(x, y);

With the plot above, we see that the 2D transformation somehow worked. But we can’t see
- which filenames are which data points
- how the modules are grouped all together
So we need to enrich the data a little bit more and search for a better, interactive visualization technique.
Let’s add the filenames to the matrix as well as nice column names. We, again, add the information about the module of a source code file to the DataFrame.
dissimilarity_2d_df = pd.DataFrame(
dissimilarity_2d,
index=commit_matrix.index,
columns=["x", "y"])
dissimilarity_2d_df['module'] = dissimilarity_2d_df.index.str.split("/").str[6]
dissimilarity_2d_df.head()
OK, here comes the ugly part: We have to transform all the data to the format our interactive visualization library pygal needs for its XY chart. We need to
- group the data my modules
- add every distance information
- for each file as well as
- the filename itself
in a specific dictionary-like data structure.
But there is nothing that can hinder us in Python and pandas. So let’s do this!
- We create a separate DataFrame named
plot_datawith the module names as index - We join the coordinates
xandyinto a tuple data structure - We use the filenames from
dissimilarity_2d_df‘s index as labels - We convert both data items to a dictionary
- We append each entry for a module to only on module entry
This gives us a new DataFrame with modules as index and per module a list of dictionary-like entries with
- the filenames as labels and
- the coordinates as values.
plot_data = pd.DataFrame(index=dissimilarity_2d_df['module'])
plot_data['value'] = tuple(zip(dissimilarity_2d_df['x'], dissimilarity_2d_df['y']))
plot_data['label'] = dissimilarity_2d_df.index
plot_data['data'] = plot_data[['label', 'value']].to_dict('records')
plot_dict = plot_data.groupby(plot_data.index).data.apply(list)
plot_dict
With this nice little data structure, we can fill pygal’s XY chart and create an interactive chart.
import pygal
xy_chart = pygal.XY(stroke=False)
[xy_chart.add(entry[0], entry[1]) for entry in plot_dict.iteritems()]
# uncomment to create the interactive chart
# xy_chart.render_in_browser()
xy_chart
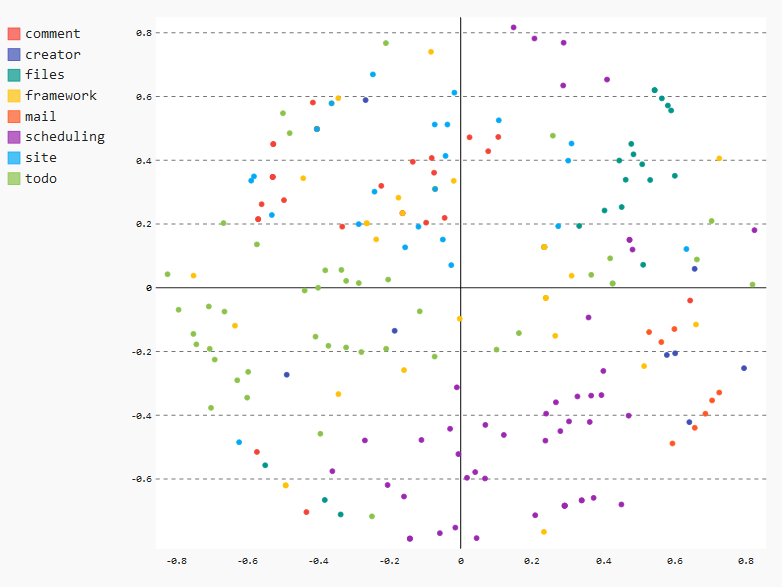
This view is a pretty cool way for checking the real change behavior of your software including an architectural perspective.
Example
Below, you see the complete data for a data point if you hover over that point:
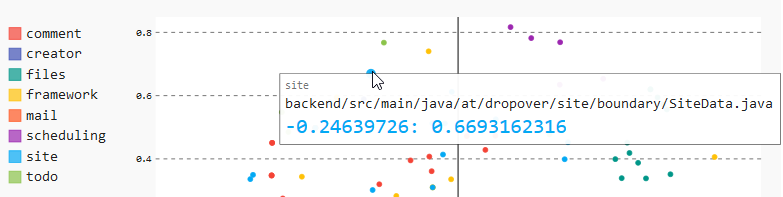
You can see the following here:
- In the upper left, you find the name of the module in the gray color
- You find the complete name of the source code file in the middle
- You can see the coordinates that MDS assigned to this data point in the color of the selected module
Let’s dive even deeper into the chart to get some insights that we can gain from our result.
Discussion
Module “mail”
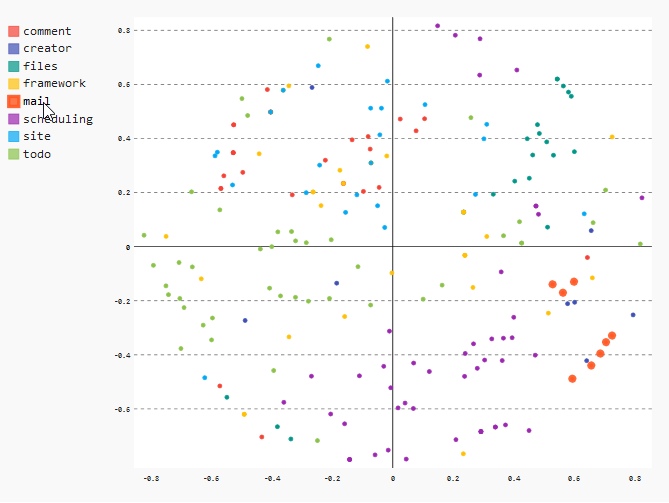
As already seen in the heatmap, we can see that all files of the “mail” module are very close together. This means that the files changed together very often.
In the XY chart, we can see this clearly when we hover over the “mail” entry in the legend on the upper left. The corresponding data points will be magnified a little bit.
Module “scheduling”
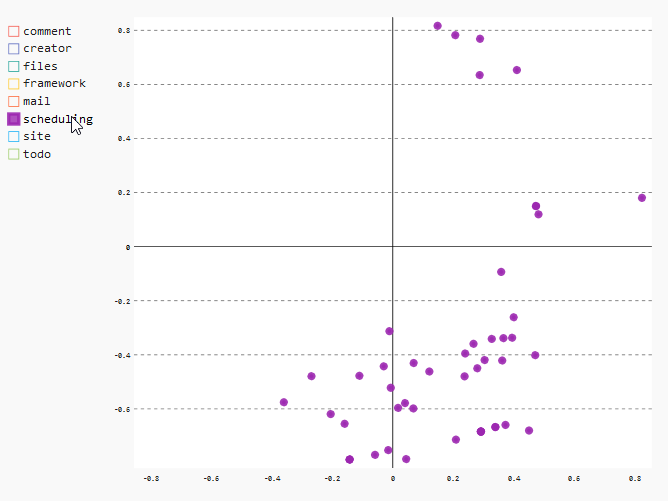
Another interesting result can be found if we take a look at the distribution of the files of the module “scheduling”. Especially the data points in the lower region of the chart indicate clearly that these files were changed almost exclusive together.
In the XY chart, we can take a look at the relevant data points by selecting just the “scheduling” data points by deselecting all the other entries in the legend.
Modules “comment”, “framework” and “site”
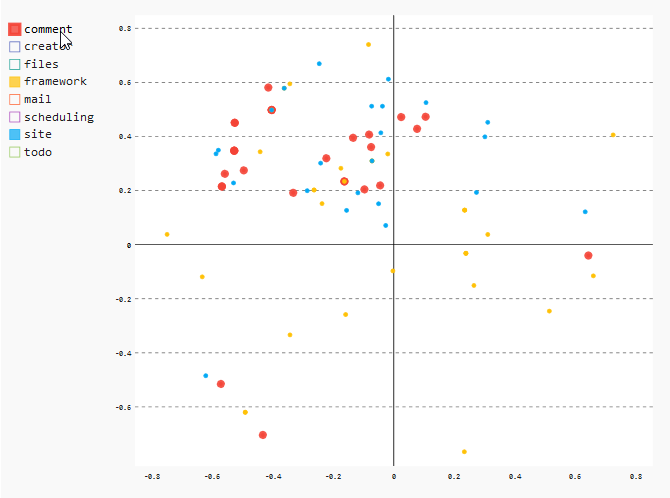
The last thing I want to show you in our example is the common change pattern for the files of the modules “comment”, “framework” and “site”. The files of these modules changed together very often, leading to a very mixed colored region in the upper middle. In case of our system under investigation, this is perfectly explainable: These three modules were developed at the beginning of the project. Due to many redesigns and refactorings, those files had to be changed all together. For these modules, it would make sense to only look at the recent development activities to find out if the code within these modules is still co-changing.
In the XY chart, just select the modules “comment”, “framework” and “site” to see the details.
Summary
We’ve seen how you can check the modularization of your software system by also taking a look at the development activities that is stored in the version control system. This gives you plenty of hints if you’ve chosen a software architecture that also fits the commit behavior of your development teams.
But there is more that we could add here: You cannot only check for modularization. You could also e. g. take a look at the commits of your teams, spotting parts that are getting changed from too many teams. You could also see if your actions taken had any effect by checking only the recent history of the commits. You can also redefine what co-changing means e. g. you define it as files that were changed on the same day, which would kind of balance out different commit styles of different developers.
But for now, we are leaving it here. You can experiment with further options on your own. You can find the complete Jupyter notebook on GitHub.