Introduction
This blog is a three-part series. See part 2 for calculation of test similarity and part 3 (upcoming) for visualization.
In an upcoming analysis, we want to calculate the structural similarity between test cases. For this, we need the information which test methods call which code in the application (the “production code”).
In this blog post, I’ll show how you can get this information by using jQAssistant for a Java application. With jQAssistant, you can scan the structural information of your software. I’ll also explain the relevant database query that delivers the information we need later on.
Dataset
I’ve scanned a small pet project of mine called “DropOver” that was originally developed as a web application for organizing parties or bar-hoppings. I’ve just added jQAssistant as a Maven plugin to my project’s Maven build (see here for a mini tutorial). The structures of this application are stored by jQAssistant in a property graph within the graph database Neo4j. A subgraph with the structural information that’s relevant for our purposes looks like this:
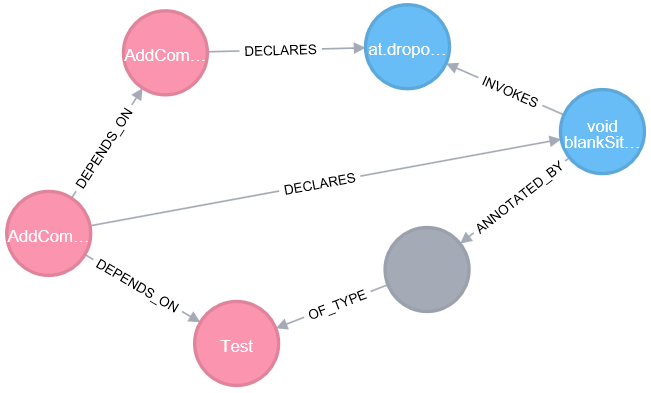
We can see the scanned software entities like Java types (red) or methods (blue) as well their relationships with each other. We can now explore the database’s content with the included Neo4j browser frontend or access the data with a programming language. I use Python (the programming language we’ll write our analysis later on) with the py2neo module (the bridge between Python and Neo4j). The information we need can be retrieved by creating and executing a Cypher query (explained in the following) – Neo4j’s language for accessing information in the property graph.
Last, we store the results in a Pandas DataFrame named invocations for a nice tabular representation of the outputs and for further analysis.
import py2neo
import pandas as pd
graph = py2neo.Graph()
query = """
MATCH
(testMethod:Method)
-[:ANNOTATED_BY]->()-[:OF_TYPE]->
(:Type {fqn:"org.junit.Test"}),
(testType:Type)-[:DECLARES]->(testMethod),
(type)-[:DECLARES]->(method:Method),
(testMethod)-[i:INVOKES]->(method)
WHERE
NOT type.name ENDS WITH "Test"
AND type.fqn STARTS WITH "at.dropover"
AND NOT method.signature CONTAINS "<init>"
RETURN
testType.name as test_type,
testMethod.signature as test_method,
type.name as prod_type,
method.signature as prod_method,
COUNT(DISTINCT i) as invocations
ORDER BY
test_type, test_method, prod_type, prod_method
"""
invocations = pd.DataFrame(graph.data(query))
# reverse sort columns for better representation
invocations = invocations[invocations.columns[::-1]]
invocations.head()
Cypher query explained
Let’s go through that query from above step by step. The Cypher query that finds all test methods that call methods of our production types works as follows:
In the MATCH clause, we start our search for particular structural information. We first identify all test methods. These are methods that are annotated by @Test, which is an annotation that the JUnit4 framework provides.
MATCH
(testMethod:Method)-[:ANNOTATED_BY]->()-[:OF_TYPE]->(:Type {fqn:"org.junit.Test"})
Next, we find all the test classes that declare (via the DECLARES relationship type) all test methods from above.
(testType:Type)-[:DECLARES]->(testMethod)
With the same approach, we first identify all the Java types and methods (at first regardless of their meaning. Later, we’ll define them as production types and methods).
(type)-[:DECLARES]->(method:Method)
Last, we find test methods that call methods of the other methods by querying the appropriate INVOKES relationship.
(testMethod)-[i:INVOKES]->(method)
In the WHERE clause, we define what we see as production type (and thus implicitly production method). We achieve this by saying that a production type is not a test and that the types must be within our application. These are all types that start with the fqn (full qualified name) at.dropover. We also filter out any calls to constructors, because those are irrelevant for our analysis.
WHERE
NOT type.name ENDS WITH "Test"
AND type.fqn STARTS WITH "at.dropover"
AND NOT method.signature CONTAINS "<init>"
In the RETURN clause, we just return the information needed for further analysis. These are all names of our test and production types as well as the signatures of the test methods and production methods. We also count the number of calls from the test methods to the production methods. This is a nice indicator for the cohesion of a test method to a production method.
RETURN
testType.name as test_type,
testMethod.signature as test_method,
type.name as prod_type,
method.signature as prod_method,
COUNT(DISTINCT i) as invocations
In the ORDER BY clause, we simply order the results in a useful way (and for reproducible results):
ORDER BY
test_type, test_method, prod_type, prod_method
A long explanation, but if you are familiar with Cypher and the underlying schema of your graph, you write those queries within half a minute.
Data export
Because we need that data in a follow-up analysis, we store the information in a semicolon-separated file.
invocations.to_csv("datasets/test_code_invocations.csv", sep=";", index=False)
Conclusion
This post was just the prelude for more in-depth analysis for structural test case similarity. We quickly got the information about which test method calls which production method. Albeit its a pure static (or structural) view of our code, it delivers valuable insights in further analysis.
Stay tuned!
You can find the original Jupyter notebook on GitHub.
Pingback:Calculating the Structural Similarity of Test Cases – feststelltaste
Pingback:Visualizing and Clustering of the Structural Similarities of Test Cases – feststelltaste