TL;DR: There is a superb open source software tool out there for scanning, documenting and validating software systems: jQAssistant.

Logo and key features of jQAssistant
jQAssistant (http://www.jqassistant.org) is a great tool for scanning and validating software structures (like Maven projects, Java bytecode or Git repositories). It also supports documenting your architectural rules and design conventions in a central place. I think jQAssistant is one of the most awesome tools out there for checking that your software complies with the conventions that you came up with. Additionally, I’m beginning to explore it’s (and the underlying Neo4J graph database’s) features for as a plain simple way for analyzing source code artifacts (see post).
I came across jQAssistant during working on some time-consuming design and code review tasks for Java-based programs. I had many boring checks to do like “is the layering of the software correctly implemented via packages and Maven modules”, “are annotations placed at the necessary places” or “are the naming conventions like mandated”. I search and I found a video of a talk about jQAassistant given by the creator Dirk Mahler. I soaked everything I could get and started to have fun with jQAssistant. Now it’s time to share some experiences with you!
In general, you can use jQAssistant
- for defining and automatically(!) validating your project specific rules on a structural level
- for creating a self-validating, living architecture documentation in AsciiDoc
- as a data source for Software Analytics
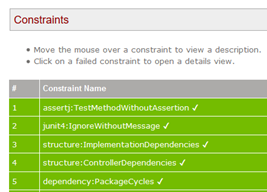
A part of the HTML report, displaying validation results
The core of jQAssistant is an embedded Neo4j graph database where all the information is stored. You can query that database with the Cypher query language (it’s like SQL, but for graphs). jQAssistant is open source and extensible via plugins.
What others do
Here are some basic examples from the jQAssistant’s documentation:
- Enforce naming conventions, e.g. EJBs, JPA entities, test classes, packages, maven modules etc.
- Validate dependencies between modules of your project
- Separate API and implementation packages
- Detect common problems like cyclic dependencies or tests without assertions
But that’s only scratching the surface. Here are some further examples of how jQAssistant is used by others:
- Self-Validating, living architecture documentation showcase based on the famous Spring PetClinic project: https://buschmais.github.io/spring-petclinic/
- A live online demo to get your hands dirty right now: https://jqassistant.org/get-started/
- Examples on how to explore source code: https://jqassistant.org/yes-we-scan-exploring-libraries/
- Comprehensive case study from E-Post Development: http://jqassistant.org/wp-content/uploads/2016/05/CaseStudy_EPOST_jQA_EN_web.pdf
- Checking for missing branch bug fixes in master https://jqassistant.org/verifying-branches-using-the-git-plugin/
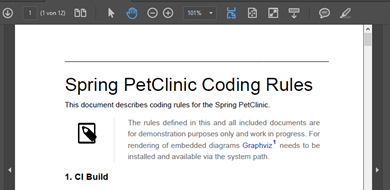
A generated, living architecture documentation in PDF
And have a look at Dirk Mahler’s talks on YouTube, where he introduces jQAssistant and shows some additional analysis:
- In English (long version): https://www.youtube.com/watch?v=6jDdhW1Wu6A
- In English (short version): https://www.youtube.com/watch?v=IBpK2cYmY-A
- In German: https://www.youtube.com/watch?v=kQr2c7yWbEA
What I’ve done far
What I primarily needed was a kind of “structural source code search engine”. I thought when you can browse through your source code in your IDE it has to be possible to do that automatically. After discovering jQAssistant, I experimented a little bit with it and begun to write down some of the architectural and programming conventions (that lay around everywhere, including different brains) as rules in an AsciiDoc file. I let jQAssistant check the compliance of rules, communicated the findings and fixed some issues that popped up.
As of today, I use it on every occasion that smells like a software analysis tasks:
- Checking database table and sequence naming conventions (e. g. the prefix of the table name in Entities’ @Table Annotation)
- Detecting violations of the vertical separation of business domains (defined by Java packages)
- Deriving basic architectural metrics (like Fan-In-Fan-Out, Package Cycles, God classes…)
- Visualizing dependencies with GraphML
- Detecting shared mutable objects statically (via the “INVOKES” and “WRITES” relationships, works static fields / Singletons)
- Scanning JProfiler’s XML export of JDBC-Hotspots to find out the root causes of performance problems by applying some heuristics (lazy loading, N+1 query problems, framework bugs, design issues, you name it)
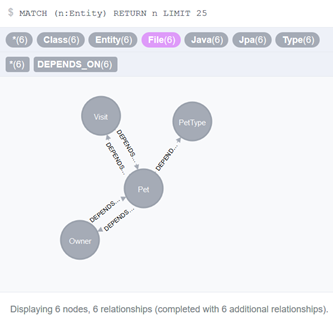
Visualizing some business entities in the Neo4j browser
I’m also completely into the Software Analytics thing, where you take some Data Science tools like Python Pandas to gain more insights into your own code base (it was the logically next step after studying computer science first and specializing in Business Intelligence / Data Mining afterward).
For analysis tasks, I often have to do the same things over and over again:
- Reading detailed information from source code repositories
- Extract structural information from source code
- Determine higher level concepts from the otherwise too detailed code
This is where jQAssistant fits in perfectly! Just lately it occurred to me that jQAssistant is an almost perfect data source for providing all those information, because jQAssistant doesn’t only scan source code! With the plugin architecture, one can easily write special scanners for other source code artifacts like Git repositories or XML files (which somebody did already). I’ve blogged about that and created a separated GitHub repository with notebooks (the notebooks are best viewed in the browser’s desktop mode). More to come in the future.
Room for improvement?
What jQAssistant delivers today is far beyond most other software quality assurance tools out there. It’s a versatile scanner, a base for living documentation, a flexible data store for software related information and many other things. I almost don’t dare to suggest some enhancements for future releases, but here they are 🙂
Support for exceptions from the rules
jQAssistant is very good at validating your rules. Sometimes it’s too good because there is a maxim “no rule without exceptions”. Especially when validating “just” conventions there are almost always some corner cases where you might not be able to follow the conventions in your source code. To be able to mark these cases as exceptions would be good. But on the other side, if it comes to lists of exceptions in architectural or design related rules, then you should question yourself if your rule makes sense at all.
Maybe this feature is already supported by jQAssistant. I didn’t have a look at the newest version 1.2.0. It could be that the new “rule parameters” feature could provide exactly be what I need (with a little bit of bending). Additionally, Dirk Mahler had the idea that one could use a special label/marker for the exceptions of rules. Both approaches are worth exploring in the near future.
Missing documentation of the scanned source code
What I’m missing personally so far is the possibility to query for in-code comments. Because jQassistant scans Java bytecode, all JavaDoc and inline code comments are missing. I would like to have a relationship between the structural elements and the code comments. But I’m very biased on this topic:
- First, I did some text mining in source code repositories with very interesting insights in the past and thus believe to see some use cases for checking structural code with comments in general.
- Second, I often need to check for “good” API documentation, e. g. checking for auto generated or false class names in the code would be a good start for detecting deficiencies. Later on, one could check if there is at least some kind of a sentence existing as a comment (with some natural language processing techniques in Python or even Neo4j itself).
- Third: Someone said to me once that “Nobody cares about code documentation. I could even copy and paste the lyrics of a Helene Fischer (a famous German singer) song as a comment and nobody would care!” I accepted that challenge to detect those kinds of comments ;-).
But as mentioned, this is a really a special case and I’m not depending on that feature. Today I’m scanning source code with Python’s Pygments library, but without relationships (Note to myself: Wait a minute, would this be an approach to scan every language’s source code into jQAssistant’s underlying Neo4j database and connect it to the already existing, structural information?).
“Critique”
This section isn’t primarily related to jQAssistant, but for all quality assuring tools out there. I’ve discussed these points with some developers mainly at meetups and blogged about it in german, so I won’t get into details here. The short story is: Many companies aren’t ready for jQAssistant, yet.
Unclear responsibilities
When it comes to the living architecture documentation capabilities of jQAssistant, the question arises, who cares and creates the architecture documentation? First, you may have some company internal doctrines and guidelines, but are those really documented in a way that everybody can understand them? Are they clearly formulated so that everybody can follow the rules while coding? Second, who feels responsible for creating the self-validation, living architecture documentation? The architects might say “well, that’s kind of coding, so we don’t do it” and the developers might just not see architectural kind of work in their responsibility, leading to a dead end.
My experience is to just do it. As a responsible developer, gather all the information that’s flying around in your company in a central AsciiDoc document and begin to write first rules for jQAssistant. You’ll see that you get addicted very quickly and then the fun starts: You will have many productive meetings (yes, they still exists!) with different people to get their thoughts transformed in clear statements, documented, formalized as rules. These rules can then automatically be check against your code base and ensure consistency (one of the key principles of successful software architectures).
Radical transparency
One of the first things that fall short if the deadline of a project is approaching is internal software quality. We as developers know that this is a bad approach, but there are “higher level decisions” that can overrule our interventions: politics. The problem is that jQAssistant works so well on discovering violations of your architecture and programming conventions that in some company it could be seen as a threat (I don’t work for these ones anymore…). It’s delivering highest transparency about how good you comply with the standards you’ve defined yourself! As a developer, you might think that this is a good thing. But think about it: When there is a tool that demonstrates that there are serious shortcomings in your software, who will be blamed? Certainly your manager. If that person doesn’t fully appreciate the high value of internal software quality, you will never show any quality assurance reports again.
Another point: After defining your rules (you think you adhere to) and the first run, there is almost always a rude awakening. You will find parts of your software that don’t fit. Then the big discussions begin: Does that tool work correctly? Is there a bug in a rule? Aren’t all the findings just exceptions from the rule? This can lead to situations where some may deny the results of the report or even are questioning the tool usage at all because otherwise violations of architectural principles have to be fixed (and fixing costs money!).
I deeply believe that these problems are just a communication problem: We as developers should thrive to better communicate the internal shortcomings of our software and the possible impact on the business. For this, we need to create transparency instead of burying our heads in sand or code. Management is relying on our ability to speak up when technical problems exist, but demand evidence that supports our statements. This is what tools like jQAssistant are made for!
Summary
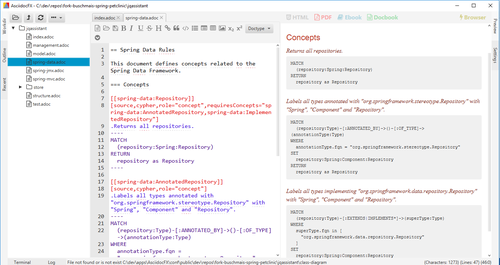
Editing an AsciiDoc document with Cypher queries in the AsciiDocFx Editor
As of today, jQAssistant is an inherent part of my software developer’s life. In my opinion, jQAssistant stands out of all other general purpose tools because it appreciates context: You define your rules in your situation from your perspective. This is a big step forward to reliable, bullet-proof software analysis tasks!
I’m very satisfied with the jQAssistant as it is and I’m curious about the future! I wish more people would take the time to get a glimpse of the possibilities of the tool.
What are you waiting for?
“Today I’m scanning source code with Python’s Pygments library, but without relationships (Note to myself: Wait a minute, would this be an approach to scan every language’s source code into jQAssistant’s underlying Neo4j database and connect it to the already existing, structural information?).”
One option is to create a python program using Pygments to get the javadoc. Whenever you detect a comment write it to a file along with its location : fully qualified name for a class, fully qualified name + method signature for a method, etc.
Then create a jQA plugin to scan this file and add comment nodes to neo4j.
Then create and apply a jQA concept that creates a relationship between a comment node and a class node (previously created by the java jQA plugin) that share the same fully qualified name . Or better, create and populate a new property “comment” to the class node and finally delete the comment nodes.
But most of these steps could be skipped if you can directly write to neo4j from your python program (I don’t think it’s possible until jQA supports neo4j 3+ and its bolt protocol).
Thanks for this great idea! I’ve just checked if I could write to the Neo4j database of jQAssistant and it works! So I wouldn’t write a plugin for this kind of seldom use case but would code it into my notebook. Will give it a try. Nice!
Pingback:Mining performance hotspots with JProfiler, jQAssistant, Neo4j and Pandas – Part 1: The Call Graph – feststelltaste
Pingback:Visualizing Production Coverage with JaCoCo, Pandas and D3 – feststelltaste
Pingback:Higher-Level Abstractions with jQAssistant and Neo4j – feststelltaste